others-How to understand CAP theorem? Understand CAP theorem with diagrams and examples
1. Purpose
In this post , I would demo how to understand the CAP theorem by illustrating it with some diagrams and examples. After reading this post, you would grasp these knowledges:
- The origins of CAP theorem
- What does C/A/P stand for and how to understand them
- What does CA/CP/AP stand for and how to understand them
2. The definition of CAP theorem
CAP theorem, also known as Brewer’s theorem, is a conjecture proposed by Eric Brewer, a computer scientist at the University of California, Berkeley, at the ACM PODC in 2000. In 2002, Seth Gilbert and Nancy Lynch of the MIT published a proof of Brewer’s conjecture, making it a recognized theorem in the field of distributed computing.
For architects who design distributed systems, CAP is a theory that must be mastered.
2.1 Definition from wikipedia
According to wikipedia, the definition of CAP theorem is as follows:
In theoretical computer science, the CAP theorem, also named Brewer’s theorem after computer scientist Eric Brewer, states that any distributed data store can only provide two of the following three guarantees:
Consistency Every read receives the most recent write or an error. Availability Every request receives a (non-error) response, without the guarantee that it contains the most recent write. Partition tolerance The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
The CAP theorem indicates that when a network partition failure happens, it must be decided whether to
- Cancel the operation and thus decrease the availability but ensure consistency or to
- Proceed with the operation and thus provide availability but risk inconsistency.
Thus, if there is a network partition, one has to choose between consistency and availability.
2.2 Definition from Robert Greiner
Robert Greiner’s self introduction from his blog :
I’m a technology executive and enterprise architect with 14+ years of diversified IT leadership, strategy, cloud transformation, delivery, and consulting experience. I also speak regularly on leadership topics and recently started a podcast.
I started my career as a software engineer my senior year of college where I got an internship at L-3 Communications and stayed there for the next five years. Afterwards, I took a software engineering position Autonomy, a UK based company which HP later purchased and finally moved to Southwest Airlines as a contractor working on southwest.com before ending up at my current position at Pariveda Solutions.
In his opinion, the CAP is defined as follows:
- Consistency: A read is guaranteed to return the most recent write for a given client.
- Availability: A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
- Partition Tolerance: The system will continue to function when network partitions occur.
Because network is not reliable in real world, so we MUST tolerate the ‘Network Partition’, then we only have two options, Consistency or Availability, e.g. CP or AP.
3. Understand the CAP theorem with diagrams and examples
According to Robert Greiner’s article, the CAP theorem targets the system that:
- are interconnected nodes , and
- share data between nodes, the data on distributed nodes should be synchonrized if there is no network partition problem
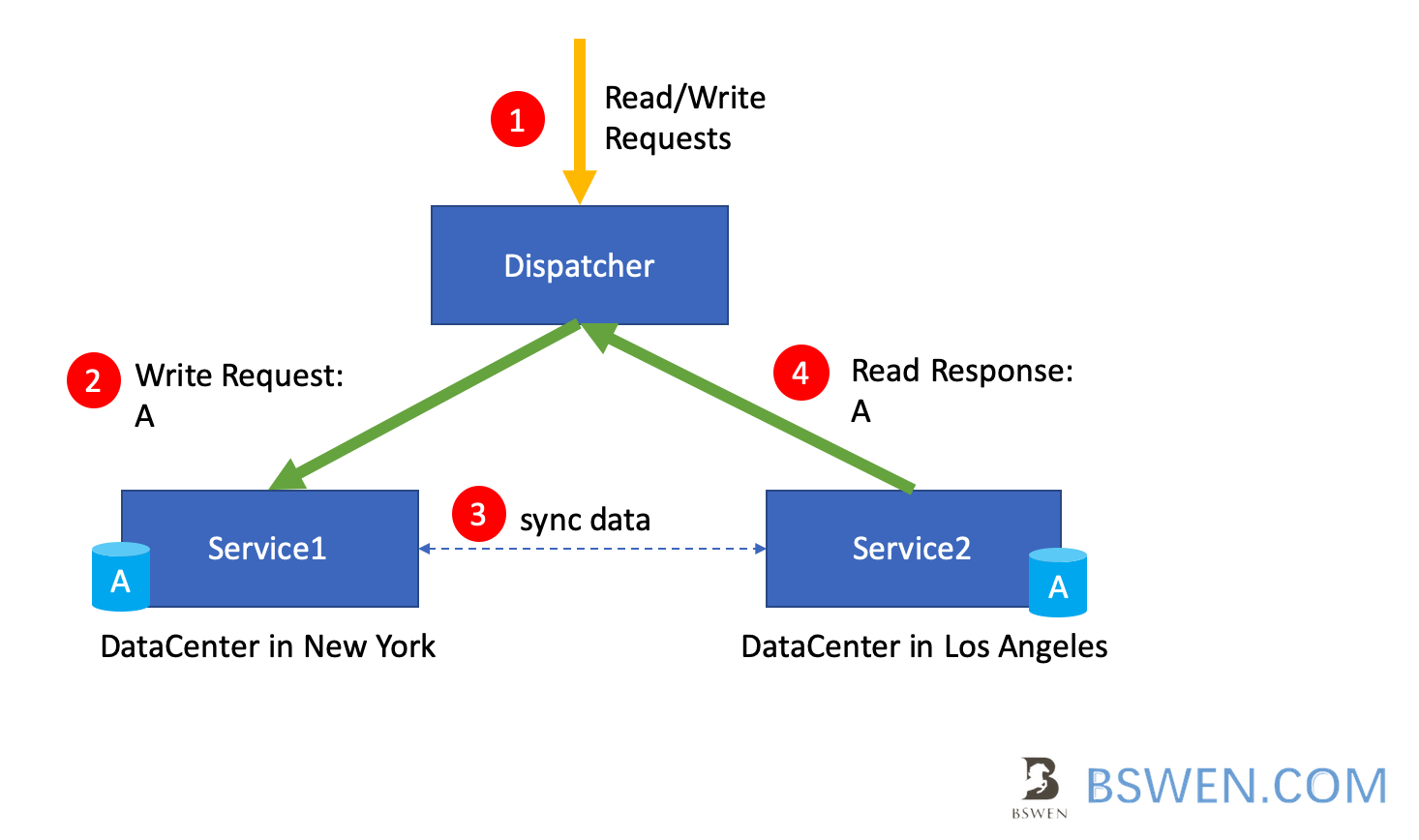
Suppose we have a distributed system as follows to serve requests from users. There are two components:
- Dispatcher: The Dispatcher is responsible for distributing the requests to services at different locations
- Service1 & Service2: the services are instances of a same service module. They are distributed at different cities(One in New York, one in Los Angeles), Each Service contains a database, which is synchronized in real time(In CAP Theorem, the network delay is ignored).
The system is working fine now:
- If user #1 send a write request to service1 at New York, the database would change to status A, then new data is synchronized to service2(Both database are synchronized in real time, network delay is ignored), so the database in Service2 is in status A too, and then
- If user #2 send a read request to service2 at Los Angeles, Service2 should return the correct data to user #2
3.1 Understand the ‘Consistency’ in CAP theorem
In database domain, there is also a ‘Consistency’ in ACID theorem:
Consistency ensures that a transaction can only bring the database from one valid state to another, maintaining database invariants: any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof. This prevents database corruption by an illegal transaction, but does not guarantee that a transaction is correct. Referential integrity guarantees the primary key – foreign key relationship. [6]
However, Consistency in CAP is defined as follows:
Consistency in CAP means A read is guaranteed to return the most recent write for a given client.
It means if the data is written successfully(finish the write transaction) in the system, clients should get the correct data from the system after the transaction.
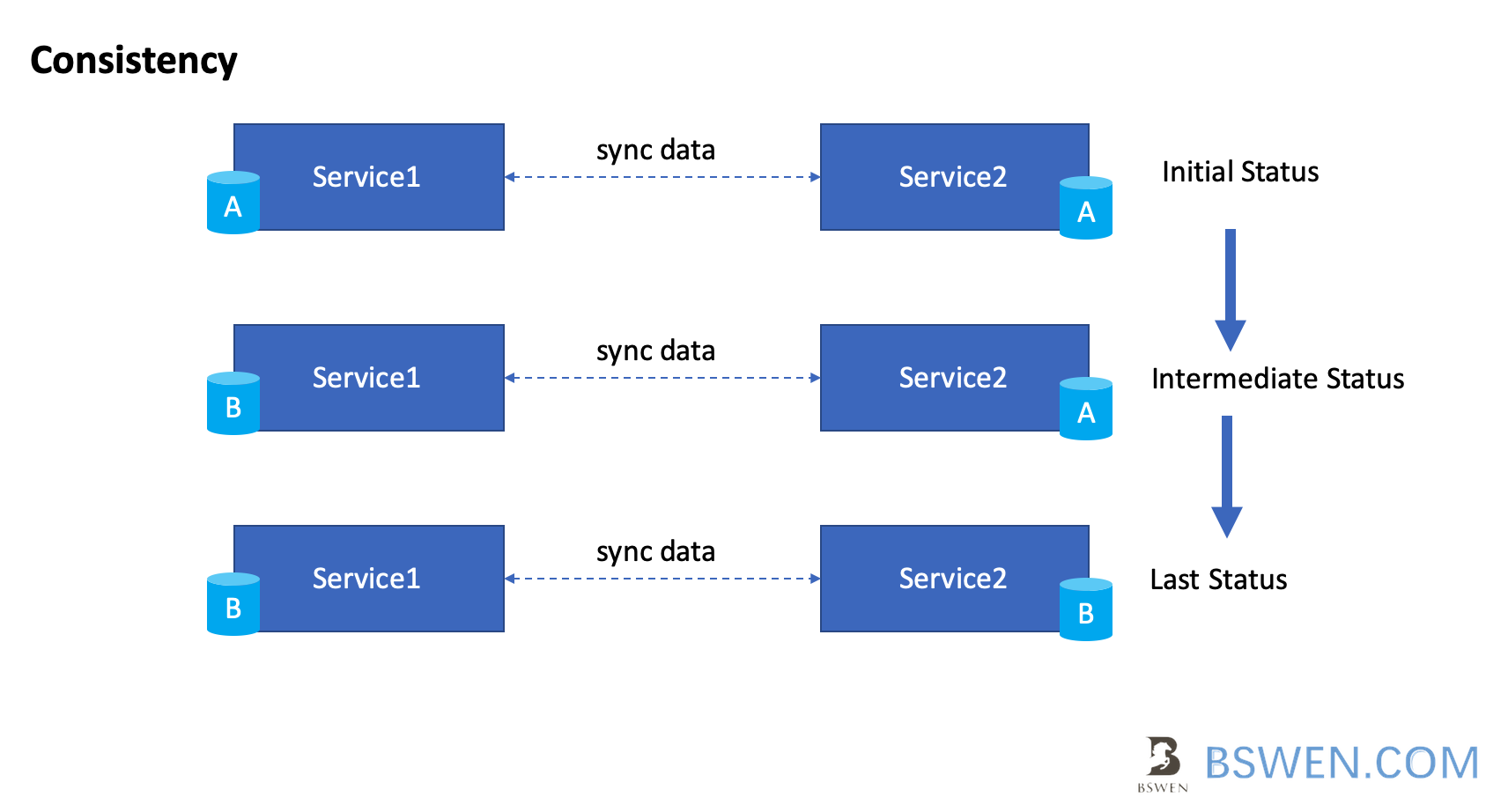
Just as the above picture shown, distributed nodes with shared data can achieve consistency by these steps:
- Initial status: both services are in the same status A
- Intermediate status: Service1 is updated(but the transaction is not commited) , its database is in status B, and the transaction is not synchonized to Service2 yet, so the database in Service2 is still in A status, if user read data from Service1 or Service2 now, they should both return A , because the transaction is still running.
- Last Status: Both databases are synchonized to status B, if user read data from Service1 or Service2 now, they should both return B , because the transaction is finished.
More information about the intermediate status:
A system has consistency if a transaction starts with the system in a consistent state, and ends with the system in a consistent state. In this model, a system can (and does) shift into an inconsistent state during a transaction, but the entire transaction gets rolled back if there is an error during any stage in the process.
If a distributed system guarantees the ‘Consistency’, it would :
- return correct data if data is synchronzed ok
- return error if data is not synchonized.
3.2 Understand the ‘Availability’ in CAP theorem
The Availability in CAP means :
A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
It has NOTHING to do with “High Availability”.
The definition of ‘Availability’ in CAP emphasizes on:
- The node is live, not down
- It should return a response
- The response content is not contrained, it can be correct or incorrect
- The response should return in an acceptable time range, don’t let the user wait too long
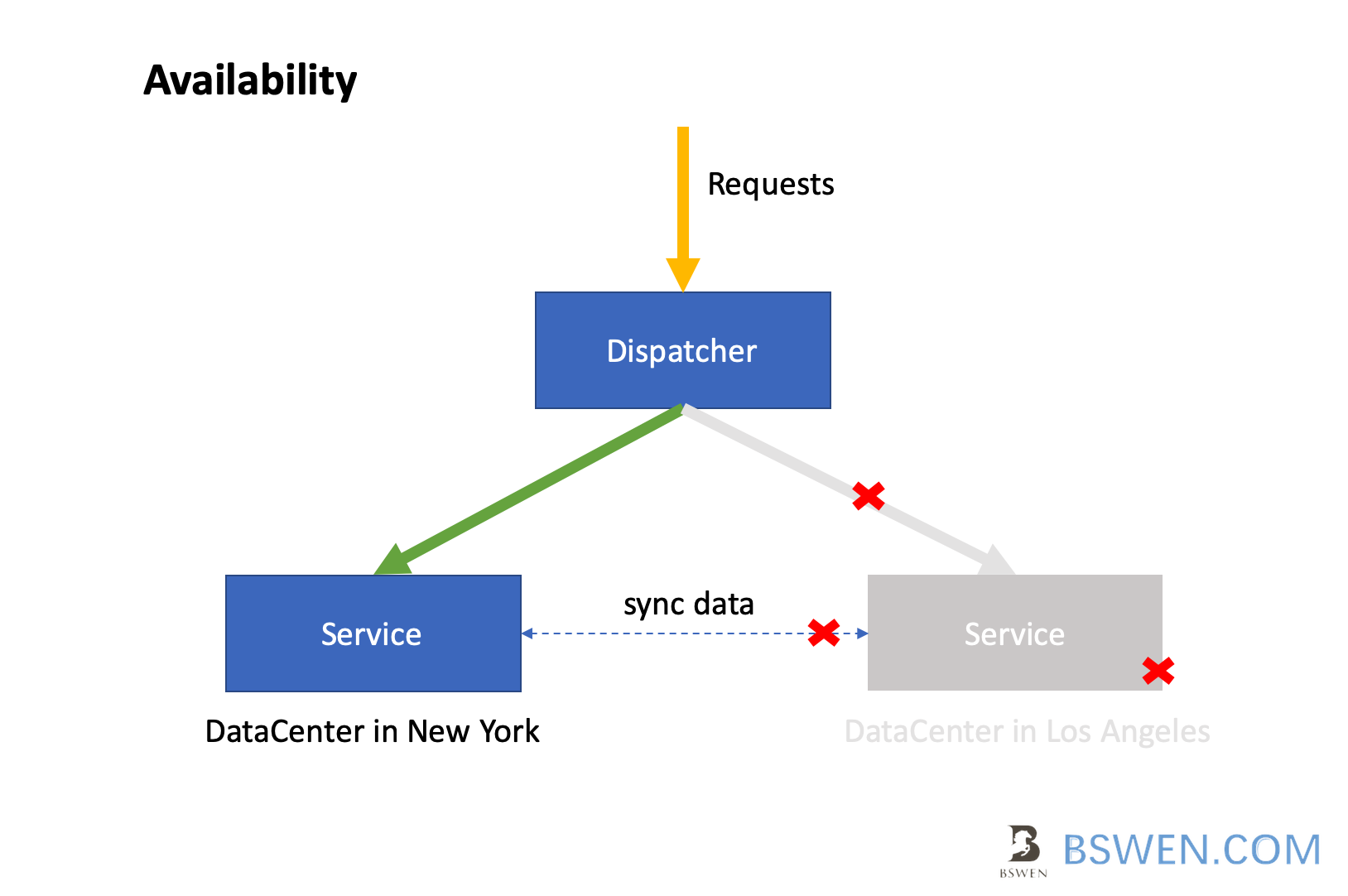
Just as the above diagram shown, the availability is as follows:
- If the node in Los Angeles is down, Then the synchronization process and the dispatcher would not continue to connect the service.
- All the requests are distributed to service in New York afterwards.
So , if any of the services is down, the whole system is still working, but the data is not synchronized among the services. If all the services are down, the system is down.
3.3 Understand the ‘Partition Tolerance’ in CAP theorem
Partition Tolerance means to tolerate the message data loss or message delay in transmission, The system will continue to function when network partitions occur, if services are deployed in different locations, they use different networks, the system should tolerate the message transmission failure ,e.g. the system is still working even if the messages are dropping.
Partition Tolerance is a guarantee that the system continues to operate despite arbitrary message loss or failure of part of the system. In other words, even if there is a network outage in the data center and some of the computers are unreachable, still the system continues to perform
The types of network partition includes:
- Message loss
- Network interruption
- Network transmission blocked
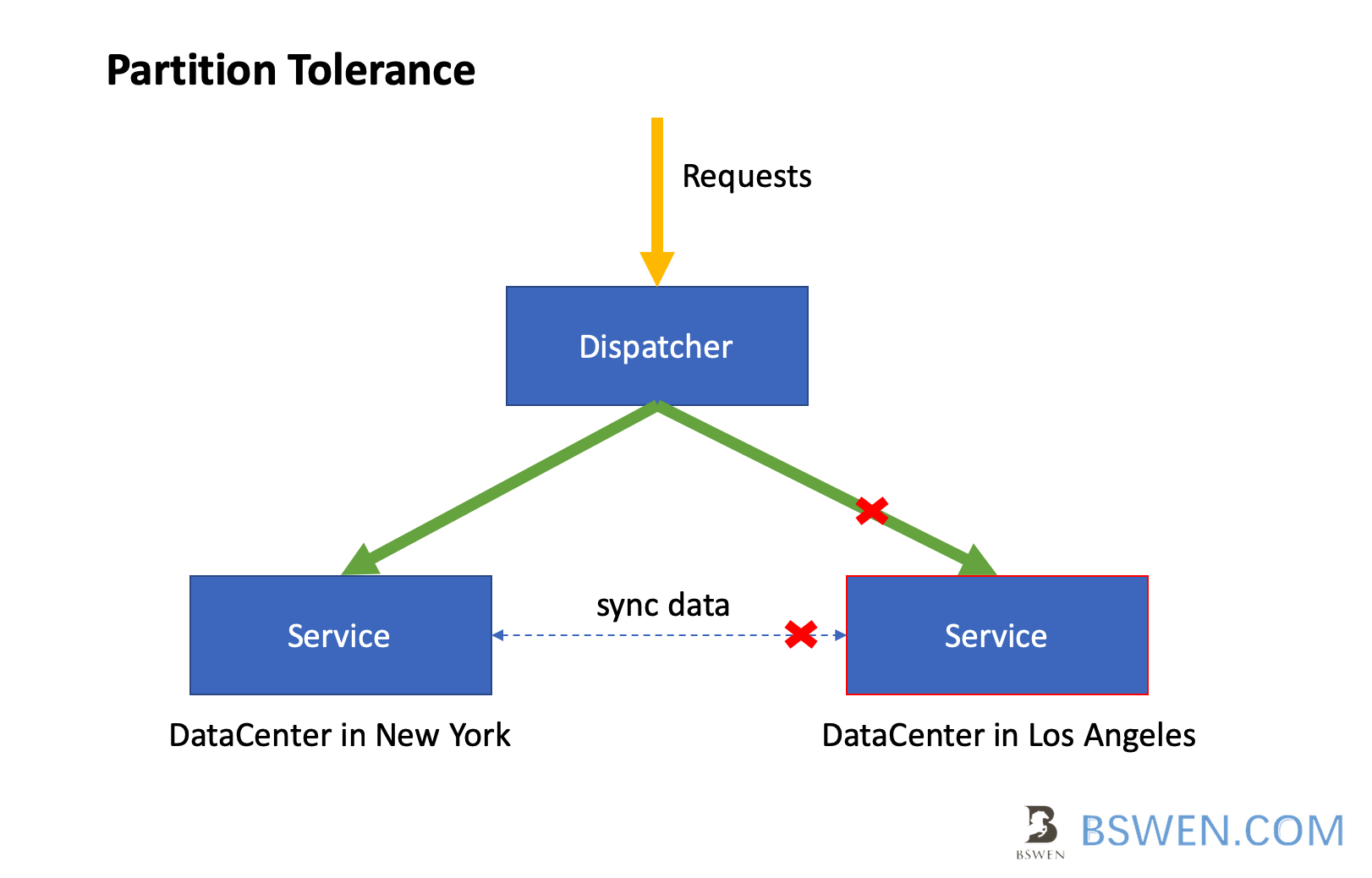
Just as the above picture shown, System should keep functioning even if there is a network partition problem(The red square) in the datacenter in Los Angeles.
- There is a network partition problem in datacenter in Los Angeles, e.g. messages are dropping or delaying.
- The dispatcher can not communicate to service in Los Angeles because of the network partition problem.
- The service in New York can not connect to service in Los Angeles too, so the synchoronization is interrupted.
- The dispatcher should route all requests to Service in New York , users still happy using the system.
You can find out that if the system is ‘Partition Tolerance’, it should keep running if any of the services encounters a network partition problem.
3.4 Understand the combination of C/A/P
There are three different combinations in C/A/P distributed systems.
- CA: Consistency and Availability.
- CP: Consistency and Partition Tolerance
- AP: Availability and Partition Tolerance
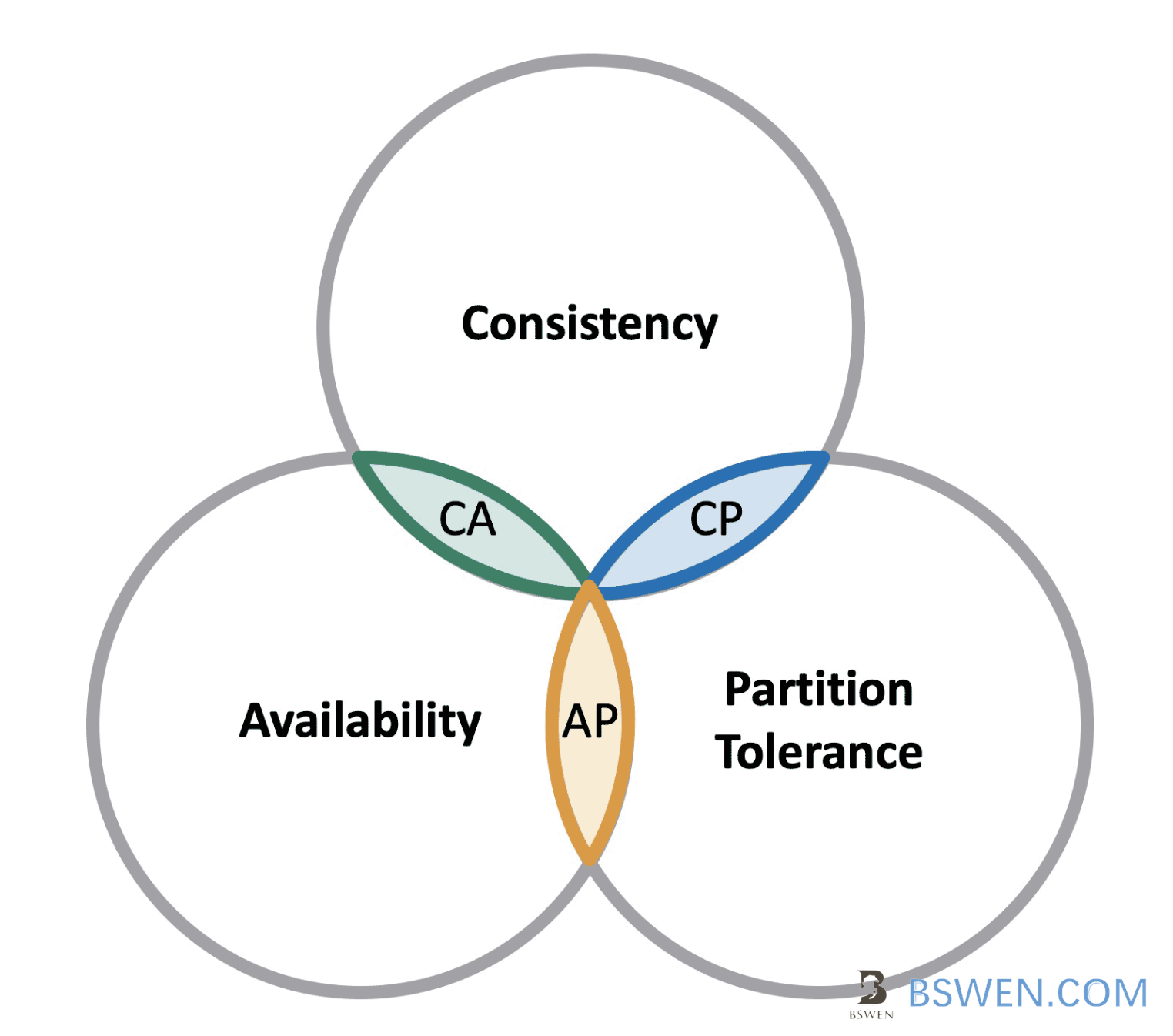
There is no ‘CAP’ , which means the system is Consistency and Availability and Partition Tolerance , because:
when a network partition problem happens(It always happen), it must be decided whether to
- Cancel the operation and thus decrease the availability but ensure consistency or to
- Proceed with the operation and thus provide availability but risk inconsistency.
So, there is no ‘CAP’ all-enabled system. If it exists, it should be a sinle-monolith system, which is not in the domain of CAP theorem target.
3.4.1 Understand the ‘CP’ system
When a system is considered as ‘CP’, it should guarantee the ‘Consistency’ and ‘Partition Tolerance’, which means:
- Every request can read/write data through any of the live nodes in the system, the data is sychronized .
- If network partitiion occurs, the system return error to prevent the desync of data between nodes.
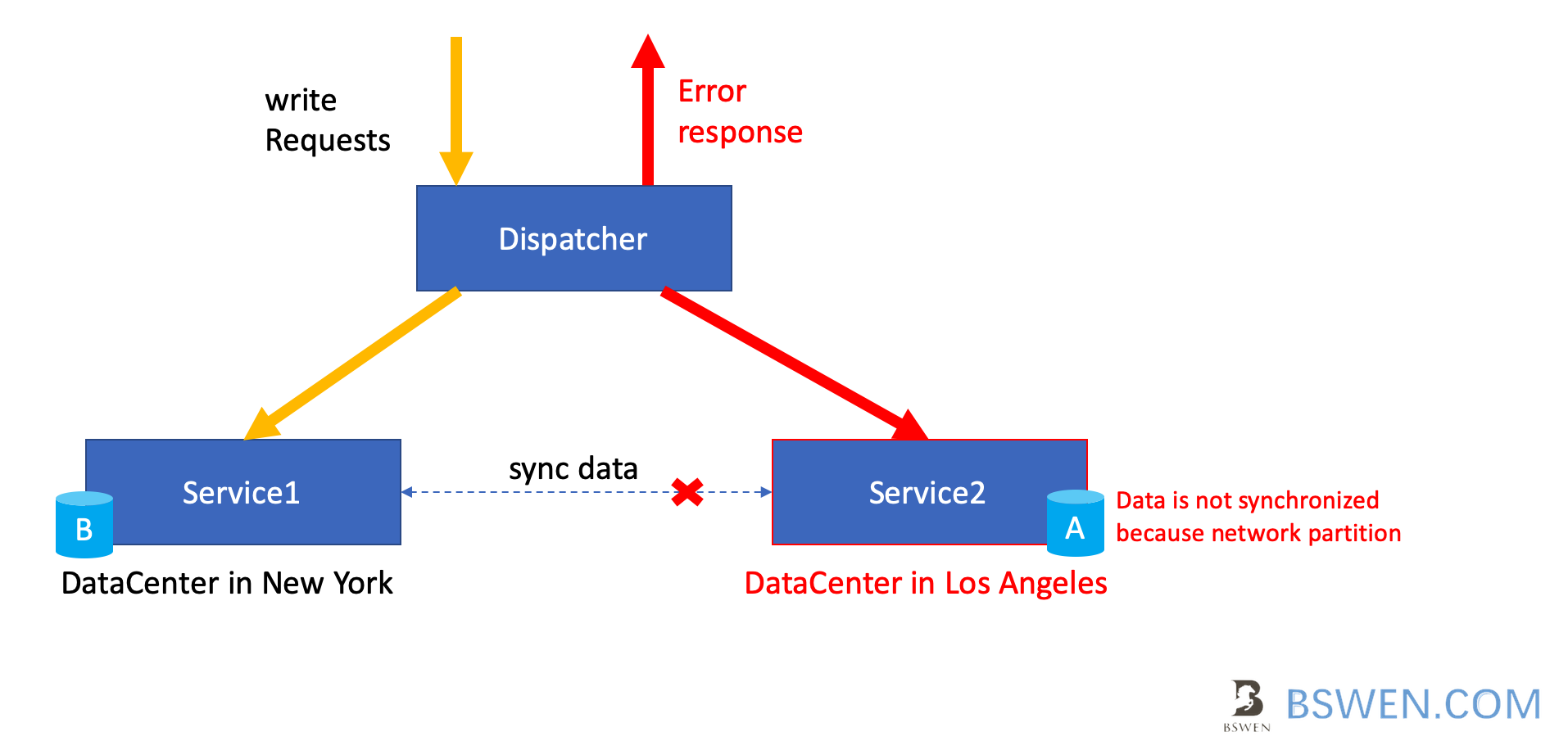
Just as the above diagram shows, the CP system has following features:
- At initial state, both databases in Service1 and Service2 are in A status
- When user write data to Service1, the data in Service1 is upgraded to B status, but at the same time, a network partition occurs
- The data is not synchronized to Service2, so
- When user try to read data from Service2, it should return error , because the data is not correct.
But how did service2 knows that there is a desync between it and Service1? It can judge the status by network heartbeating or by internal error due to the network partition, it should return error if it can not insure the synchronzation between it and Service1.
3.4.2 Understand the ‘AP’ system
When a system is considered as ‘AP’, it should guarantee the ‘Availability’ and ‘Partition Tolerance’, which means:
- Every request returns the most recent version of the data you have, which could be stale .
- If network partitiion occurs, the system return a response(which could be stale) to keep the service available.
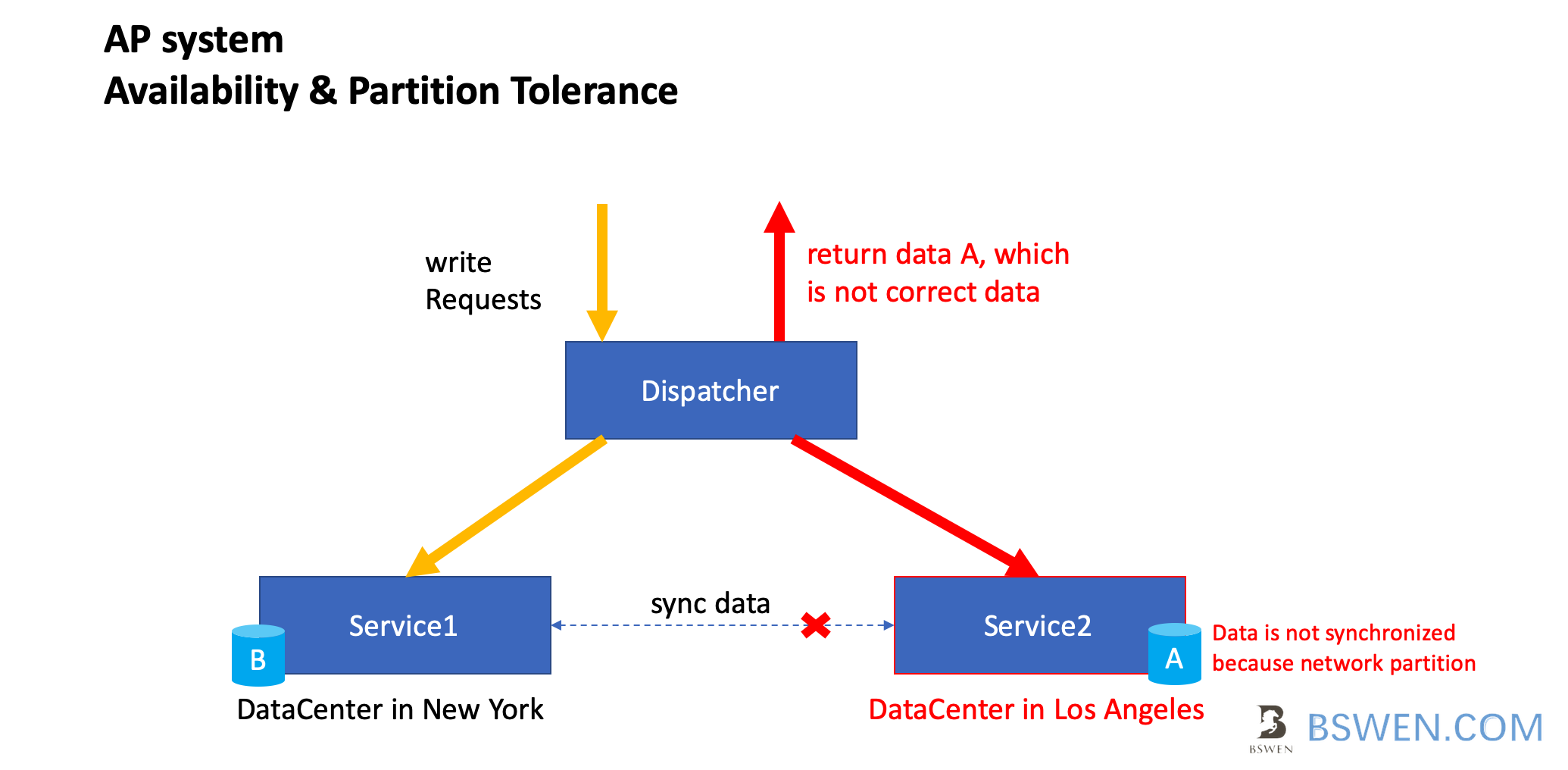
Just as the above diagram shows, the AP system has following features:
- At initial state, both databases in Service1 and Service2 are in A status
- When user write data to Service1, the data in Service1 is upgraded to B status, but at the same time, a network partition occurs
- The data is not synchronized to Service2, so
- When user try to read data from Service2, to guarantee Availability ,it should return a reponse, which is A, we all know it’s incorrect, but in some scenarios, it is acceptable.
- The desync problem would be solved when the network partition is over, and when Service2 is resumed, the database is synchonized at last(Just like BASE theorem).
3.4.3 Understand the ‘CA’ system
According to the above description, the distributed systems that sacrifice the ‘Partition Tolerance ‘ should not exist in real word, because:
- You can not sacrifice ‘Partition Tolerance ‘ , because every customer want the system keep running even if some of the nodes in your system is not available.
- The network partition is always happening in real world, because network is not reliable.
You can refer to this article to get a more sophisticated point.
4. Summary
In this post, I tried to understand the CAP theorum by some diagrams and examples, hope it helps for you to master the theorem .